-40b48f12d058417caa5388c789499b49.JPG)


1.操作篇
参考《Mysql必知必会》对着书敲了一遍
数据内容:
https://forta.com/books/0135182794/
DBMS:sqlyog
cmd
1.1 了解数据库和表
显示数据库
show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| tysql |
+--------------------+
选择数据库
use tysql
提示 Database changed
查看数据库表的列表
show tables;
+-----------------+
| Tables_in_tysql |
+-----------------+
| customers |
| orderitems |
| orders |
| products |
| vendors |
+-----------------+
5 rows in set (0.00 sec)
SHOW TABLES;返回当前选择的数据库内可用表的列表。
SHOW也可以用来显示表列:
show columns from customers;
+--------------+-----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-----------+------+-----+---------+-------+
| cust_id | char(10) | NO | PRI | NULL | |
| cust_name | char(50) | NO | | NULL | |
| cust_address | char(50) | YES | | NULL | |
| cust_city | char(50) | YES | | NULL | |
| cust_state | char(5) | YES | | NULL | |
| cust_zip | char(10) | YES | | NULL | |
| cust_country | char(50) | YES | | NULL | |
| cust_contact | char(50) | YES | | NULL | |
| cust_email | char(255) | YES | | NULL | |
+--------------+-----------+------+-----+---------+-------+
SHOW COLUMNS 要求给出一个表名( 这个例子中的FROM customers),它对每个字段返回一行,行中包含字段名、数据类型、是否允许NULL、键信息、默认值以及其他信息(如字段cust_id的auto_increment)。
MySQL支持用DESCRIBE作为SHOW COLUMNS FROM的一种快捷方式
describe customers;
+--------------+-----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-----------+------+-----+---------+-------+
| cust_id | char(10) | NO | PRI | NULL | |
| cust_name | char(50) | NO | | NULL | |
| cust_address | char(50) | YES | | NULL | |
| cust_city | char(50) | YES | | NULL | |
| cust_state | char(5) | YES | | NULL | |
| cust_zip | char(10) | YES | | NULL | |
| cust_country | char(50) | YES | | NULL | |
| cust_contact | char(50) | YES | | NULL | |
| cust_email | char(255) | YES | | NULL | |
+--------------+-----------+------+-----+---------+-------+
1.2 SELECT 语句
为了使用SELECT 检索表数据,必须至少给出两条信息 -- 想选择什么,以及从什么地方选择。
检索单个列
select prod_name
from products;
+----------------+
| prod_name |
+----------------+
| .5 ton anvil |
| 1 ton anvil |
| 2 ton anvil |
| Detonator |
| Bird seed |
| Carrots |
| Fuses |
| JetPack 1000 |
| JetPack 2000 |
| Oil can |
| Safe |
| Sling |
| TNT (1 stick) |
| TNT (5 sticks) |
+----------------+
检索多个列
select prod_id,prod_name,prod_price
from products;
+---------+----------------+------------+
| prod_id | prod_name | prod_price |
+---------+----------------+------------+
| ANV01 | .5 ton anvil | 5.99 |
| ANV02 | 1 ton anvil | 9.99 |
| ANV03 | 2 ton anvil | 14.99 |
| DTNTR | Detonator | 13.00 |
| FB | Bird seed | 10.00 |
| FC | Carrots | 2.50 |
| FU1 | Fuses | 3.42 |
| JP1000 | JetPack 1000 | 35.00 |
| JP2000 | JetPack 2000 | 55.00 |
| OL1 | Oil can | 8.99 |
| SAFE | Safe | 50.00 |
| SLING | Sling | 4.49 |
| TNT1 | TNT (1 stick) | 2.50 |
| TNT2 | TNT (5 sticks) | 10.00 |
+---------+----------------+------------+
检索所有列
+---------+---------+----------------+------------+----------------------------------------------------------------+
| prod_id | vend_id | prod_name | prod_price | prod_desc |
+---------+---------+----------------+------------+----------------------------------------------------------------+
| ANV01 | 1001 | .5 ton anvil | 5.99 | .5 ton anvil, black, complete with handy hook |
| ANV02 | 1001 | 1 ton anvil | 9.99 | 1 ton anvil, black, complete with handy hook and carrying case |
| ANV03 | 1001 | 2 ton anvil | 14.99 | 2 ton anvil, black, complete with handy hook and carrying case |
| DTNTR | 1003 | Detonator | 13.00 | Detonator (plunger powered), fuses not included |
| FB | 1003 | Bird seed | 10.00 | Large bag (suitable for road runners) |
| FC | 1003 | Carrots | 2.50 | Carrots (rabbit hunting season only) |
| FU1 | 1002 | Fuses | 3.42 | 1 dozen, extra long |
| JP1000 | 1005 | JetPack 1000 | 35.00 | JetPack 1000, intended for single use |
| JP2000 | 1005 | JetPack 2000 | 55.00 | JetPack 2000, multi-use |
| OL1 | 1002 | Oil can | 8.99 | Oil can, red |
| SAFE | 1003 | Safe | 50.00 | Safe with combination lock |
| SLING | 1003 | Sling | 4.49 | Sling, one size fits all |
| TNT1 | 1003 | TNT (1 stick) | 2.50 | TNT, red, single stick |
| TNT2 | 1003 | TNT (5 sticks) | 10.00 | TNT, red, pack of 10 sticks |
+---------+---------+----------------+------------+----------------------------------------------------------------+
1.3 只显示不同的值 distinct
只要一个列中不同的值 使用 distinct
不使用distinct
select vend_id
from products;
+---------+
| vend_id |
+---------+
| 1001 |
| 1001 |
| 1001 |
| 1002 |
| 1002 |
| 1003 |
| 1003 |
| 1003 |
| 1003 |
| 1003 |
| 1003 |
| 1003 |
| 1005 |
| 1005 |
+---------+
使用distinct
select distinct vend_id # distinct 必须在 列的前面
from products;
+---------+
| vend_id |
+---------+
| 1001 |
| 1002 |
| 1003 |
| 1005 |
+---------+
1.4 限制行数 使用limit
select prod_name
from products
limit 5; # 返回前5行
+--------------+
| prod_name |
+--------------+
| .5 ton anvil |
| 1 ton anvil |
| 2 ton anvil |
| Detonator |
| Bird seed |
+--------------+
select prod_name
from products
limit 5,5;# 返回第5行之后的5行,也就是从第6行开始数

所以,带一个值的LIMIT总是从第一行开始,给出的数为返回的行数。(可以认为默认第一参数为0)带两个值的LIMIT可以指定从行号为第一个值的位置开始。
第一参数设置为0
select prod_name
from products
limit 0,5;
+--------------+
| prod_name |
+--------------+
| .5 ton anvil |
| 1 ton anvil |
| 2 ton anvil |
| Detonator |
| Bird seed |
+--------------+
MySQL 5支持LIMIT的另一种替代语法。
LIMIT 4 OFFSET 3意为从行3开始取4行,就像LIMIT 3, 4
一样。
select prod_name
from products
limit 5 offset 0;
1.5 使用完全限定的表命 .
select products.prod_name
from products;
+----------------+
| prod_name |
+----------------+
| .5 ton anvil |
| 1 ton anvil |
| 2 ton anvil |
| Detonator |
| Bird seed |
| Carrots |
| Fuses |
| JetPack 1000 |
| JetPack 2000 |
| Oil can |
| Safe |
| Sling |
| TNT (1 stick) |
| TNT (5 sticks) |
+----------------+
当然表命也可以限制
select products.prod_name
from tysql.products;
+----------------+
| prod_name |
+----------------+
| .5 ton anvil |
| 1 ton anvil |
| 2 ton anvil |
| Detonator |
| Bird seed |
| Carrots |
| Fuses |
| JetPack 1000 |
| JetPack 2000 |
| Oil can |
| Safe |
| Sling |
| TNT (1 stick) |
| TNT (5 sticks) |
+----------------+
1.6 排序数据 order by
select products.prod_name
from products
order by prod_name;
+----------------+
| prod_name |
+----------------+
| .5 ton anvil |
| 1 ton anvil |
| 2 ton anvil |
| Bird seed |
| Carrots |
| Detonator |
| Fuses |
| JetPack 1000 |
| JetPack 2000 |
| Oil can |
| Safe |
| Sling |
| TNT (1 stick) |
| TNT (5 sticks) |
+----------------+
对比上一个语句的查询结果可以发现是排好序的。
也可以按照多个条件结合然后去排序。
select products.prod_name
from tysql.products
order by prod_price,prod_name;
+----------------+
| prod_name |
+----------------+
| Carrots |
| TNT (1 stick) |
| Fuses |
| Sling |
| .5 ton anvil |
| Oil can |
| 1 ton anvil |
| Bird seed |
| TNT (5 sticks) |
| Detonator |
| 2 ton anvil |
| JetPack 1000 |
| Safe |
| JetPack 2000 |
+----------------+
先按照价格排序,然后按照名字排序
指定排序方向
使用desc
select products.prod_name
from tysql.products
order by prod_name desc;
+----------------+
| prod_name |
+----------------+
| TNT (5 sticks) |
| TNT (1 stick) |
| Sling |
| Safe |
| Oil can |
| JetPack 2000 |
| JetPack 1000 |
| Fuses |
| Detonator |
| Carrots |
| Bird seed |
| 2 ton anvil |
| 1 ton anvil |
| .5 ton anvil |
+----------------+
对价格使用降序排序,name使用升序排序
如果想所有的列都是降序排序,则需要每个列的后面都指明desc。
select prod_id, prod_price, prod_name
from products
order by prod_price desc, prod_name;
+---------+------------+----------------+
| prod_id | prod_price | prod_name |
+---------+------------+----------------+
| JP2000 | 55.00 | JetPack 2000 |
| SAFE | 50.00 | Safe |
| JP1000 | 35.00 | JetPack 1000 |
| ANV03 | 14.99 | 2 ton anvil |
| DTNTR | 13.00 | Detonator |
| FB | 10.00 | Bird seed |
| TNT2 | 10.00 | TNT (5 sticks) |
| ANV02 | 9.99 | 1 ton anvil |
| OL1 | 8.99 | Oil can |
| ANV01 | 5.99 | .5 ton anvil |
| SLING | 4.49 | Sling |
| FU1 | 3.42 | Fuses |
| FC | 2.50 | Carrots |
| TNT1 | 2.50 | TNT (1 stick) |
+---------+------------+----------------+
select prod_id, prod_price, prod_name
from products
order by prod_price desc, prod_name desc;
可以看到最后的价格2.5对应的名字进行了降序排序
+---------+------------+----------------+
| prod_id | prod_price | prod_name |
+---------+------------+----------------+
| JP2000 | 55.00 | JetPack 2000 |
| SAFE | 50.00 | Safe |
| JP1000 | 35.00 | JetPack 1000 |
| ANV03 | 14.99 | 2 ton anvil |
| DTNTR | 13.00 | Detonator |
| TNT2 | 10.00 | TNT (5 sticks) |
| FB | 10.00 | Bird seed |
| ANV02 | 9.99 | 1 ton anvil |
| OL1 | 8.99 | Oil can |
| ANV01 | 5.99 | .5 ton anvil |
| SLING | 4.49 | Sling |
| FU1 | 3.42 | Fuses |
| TNT1 | 2.50 | TNT (1 stick) |
| FC | 2.50 | Carrots |
+---------+------------+----------------+
order by desc limit 组合找到一个列中最大的
select prod_price
from products
order by prod_price desc
limit 1;
降序排列找到最后一个 就是最大的
+------------+
| prod_price |
+------------+
| 55.00 |
+------------+
1.7 使用 where 限定
select prod_name, prod_price
from products
where prod_price = 2.50;
限定 价格为 2.50
+---------------+------------+
| prod_name | prod_price |
+---------------+------------+
| Carrots | 2.50 |
| TNT (1 stick) | 2.50 |
+---------------+------------+
在一起使用order by 与 where 子句的时候,应该让where在前面
mysql> select prod_name, prod_price
-> from products
-> where prod_price > 5.0 order by prod_price;
+----------------+------------+
| prod_name | prod_price |
+----------------+------------+
| .5 ton anvil | 5.99 |
| Oil can | 8.99 |
| 1 ton anvil | 9.99 |
| Bird seed | 10.00 |
| TNT (5 sticks) | 10.00 |
| Detonator | 13.00 |
| 2 ton anvil | 14.99 |
| JetPack 1000 | 35.00 |
| Safe | 50.00 |
| JetPack 2000 | 55.00 |
+----------------+------------+
如果命令是下面的会报错 order by 在where前面报错
where order by prod_price where prod_price > 5.0;
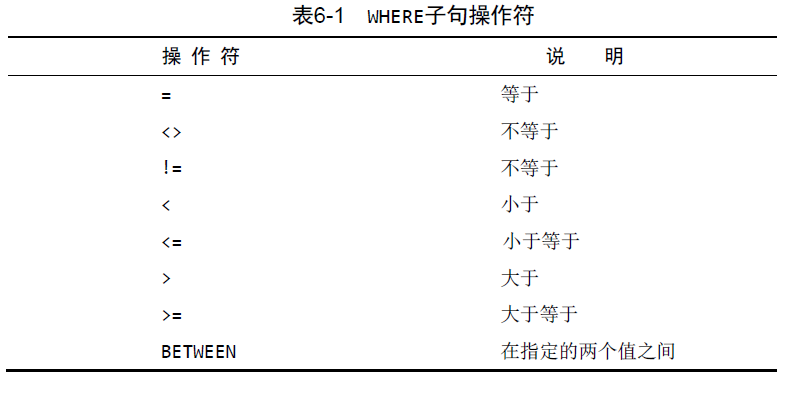
检查单个值
mysql> select prod_name, prod_price
-> from products
-> where prod_name = 'fuses';
+-----------+------------+
| prod_name | prod_price |
+-----------+------------+
| Fuses | 3.42 |
+-----------+------------+
价格小于10
mysql> select prod_name, prod_price
-> from products
-> where prod_price < 10;
+---------------+------------+
| prod_name | prod_price |
+---------------+------------+
| .5 ton anvil | 5.99 |
| 1 ton anvil | 9.99 |
| Carrots | 2.50 |
| Fuses | 3.42 |
| Oil can | 8.99 |
| Sling | 4.49 |
| TNT (1 stick) | 2.50 |
+---------------+------------+
价格小于等于10
mysql> select prod_name, prod_price
-> from products
-> where prod_price <= 10;
+----------------+------------+
| prod_name | prod_price |
+----------------+------------+
| .5 ton anvil | 5.99 |
| 1 ton anvil | 9.99 |
| Bird seed | 10.00 |
| Carrots | 2.50 |
| Fuses | 3.42 |
| Oil can | 8.99 |
| Sling | 4.49 |
| TNT (1 stick) | 2.50 |
| TNT (5 sticks) | 10.00 |
+----------------+------------+
不匹配检测
mysql> select vend_id, prod_name
-> from products
-> where vend_id <> 1003;
+---------+--------------+
| vend_id | prod_name |
+---------+--------------+
| 1001 | .5 ton anvil |
| 1001 | 1 ton anvil |
| 1001 | 2 ton anvil |
| 1002 | Fuses |
| 1002 | Oil can |
| 1005 | JetPack 1000 |
| 1005 | JetPack 2000 |
+---------+--------------+
查找范围内的数据
mysql> select prod_name, prod_price
-> from products
-> where prod_price between 5 and 10;
+----------------+------------+
| prod_name | prod_price |
+----------------+------------+
| .5 ton anvil | 5.99 |
| 1 ton anvil | 9.99 |
| Bird seed | 10.00 |
| Oil can | 8.99 |
| TNT (5 sticks) | 10.00 |
+----------------+------------+
**检索空值 ** 空值并不是值为0
mysql> select cust_id
-> from customers
-> where cust_email is null;
+---------+
| cust_id |
+---------+
| 10002 |
| 10005 |
+---------+
1.8 AND操作符
mysql> select prod_id, prod_price, prod_name
-> from products
-> where vend_id = 1003 and prod_price <= 10;
+---------+------------+----------------+
| prod_id | prod_price | prod_name |
+---------+------------+----------------+
| FB | 10.00 | Bird seed |
| FC | 2.50 | Carrots |
| SLING | 4.49 | Sling |
| TNT1 | 2.50 | TNT (1 stick) |
| TNT2 | 10.00 | TNT (5 sticks) |
+---------+------------+----------------+
此SQL语句检索由供应商1003制造且价格小于等于10美元的所有产品的名称和价格。
1.9 OR操作符
OR操作符与AND操作符不同,它指示MySQL检索匹配任一条件的行。
mysql> select prod_name, prod_price
-> from products
-> where vend_id = 1002 or vend_id = 1003;
+----------------+------------+
| prod_name | prod_price |
+----------------+------------+
| Fuses | 3.42 |
| Oil can | 8.99 |
| Detonator | 13.00 |
| Bird seed | 10.00 |
| Carrots | 2.50 |
| Safe | 50.00 |
| Sling | 4.49 |
| TNT (1 stick) | 2.50 |
| TNT (5 sticks) | 10.00 |
+----------------+------------+
此SQL语句检索由任一个指定供应商制造的所有产品的产品名和价格。
1.10 计算次序 (and 优先级大于 or)
mysql> select prod_name, prod_price
-> from products
-> where vend_id = 1002 or vend_id = 1003 and prod_price >= 10;
+----------------+------------+
| prod_name | prod_price |
+----------------+------------+
| Fuses | 3.42 |
| Oil can | 8.99 |
| Detonator | 13.00 |
| Bird seed | 10.00 |
| Safe | 50.00 |
| TNT (5 sticks) | 10.00 |
+----------------+------------+
使用括号:
mysql> select prod_name, prod_price
-> from products
-> where (vend_id = 1002 or vend_id = 1003) and prod_price >= 10;
+----------------+------------+
| prod_name | prod_price |
+----------------+------------+
| Detonator | 13.00 |
| Bird seed | 10.00 |
| Safe | 50.00 |
| TNT (5 sticks) | 10.00 |
+----------------+------------+
1.11 使用in操作符 (与or功能一致)
mysql> select prod_name, prod_price
-> from products
-> where vend_id in (1002,1003)
-> order by prod_name;
+----------------+------------+
| prod_name | prod_price |
+----------------+------------+
| Bird seed | 10.00 |
| Carrots | 2.50 |
| Detonator | 13.00 |
| Fuses | 3.42 |
| Oil can | 8.99 |
| Safe | 50.00 |
| Sling | 4.49 |
| TNT (1 stick) | 2.50 |
| TNT (5 sticks) | 10.00 |
+----------------+------------+
与使用or的语句 功能一致
mysql> select prod_name, prod_price
-> from products
-> where vend_id = 1002 or vend_id = 1003
-> order by prod_name;
+----------------+------------+
| prod_name | prod_price |
+----------------+------------+
| Bird seed | 10.00 |
| Carrots | 2.50 |
| Detonator | 13.00 |
| Fuses | 3.42 |
| Oil can | 8.99 |
| Safe | 50.00 |
| Sling | 4.49 |
| TNT (1 stick) | 2.50 |
| TNT (5 sticks) | 10.00 |
+----------------+------------+
1.12 使用NOT 操作符
mysql> select prod_name, prod_price
-> from products
-> where vend_id not in (1002,1003)
-> order by prod_name;
+--------------+------------+
| prod_name | prod_price |
+--------------+------------+
| .5 ton anvil | 5.99 |
| 1 ton anvil | 9.99 |
| 2 ton anvil | 14.99 |
| JetPack 1000 | 35.00 |
| JetPack 2000 | 55.00 |
+--------------+------------+
in 也可以指定3个
mysql> select prod_name, prod_price, vend_id
-> from products
-> where vend_id not in (1002,1003,1005)
-> order by prod_name;
+--------------+------------+---------+
| prod_name | prod_price | vend_id |
+--------------+------------+---------+
| .5 ton anvil | 5.99 | 1001 |
| 1 ton anvil | 9.99 | 1001 |
| 2 ton anvil | 14.99 | 1001 |
+--------------+------------+---------+
1.13使用like 通配符
百分号 % 通配符
% 表示任何字符出现任意次数
% 匹配后面
mysql> select prod_id, prod_name
-> from products
-> where prod_name like 'jet%';
+---------+--------------+
| prod_id | prod_name |
+---------+--------------+
| JP1000 | JetPack 1000 |
| JP2000 | JetPack 2000 |
+---------+--------------+
% 匹配前面
mysql> select prod_id, prod_name
-> from products
-> where prod_name like '%anvil';
+---------+--------------+
| prod_id | prod_name |
+---------+--------------+
| ANV01 | .5 ton anvil |
| ANV02 | 1 ton anvil |
| ANV03 | 2 ton anvil |
+---------+--------------+
匹配中间
mysql> select prod_name
-> from products
-> where prod_name like 's%e';
+-----------+
| prod_name |
+-----------+
| Safe |
+-----------+
1.14 使用下划线 _ 通配符
另一个有用的通配符是下划线(_)。下划线的用途与%一样,但下划线只匹配单个字符而不是多个字符。
mysql> select prod_id, prod_name
-> from products
-> where prod_name like '_ ton anvil';
+---------+-------------+
| prod_id | prod_name |
+---------+-------------+
| ANV02 | 1 ton anvil |
| ANV03 | 2 ton anvil |
+---------+-------------+
使用 % 也可以达到一样的效果,但是% 与 _ 不同 % 可以匹配多个,_ 只能匹配一个。
mysql> select prod_id, prod_name
-> from products
-> where prod_name like '%ton anvil';
+---------+--------------+
| prod_id | prod_name |
+---------+--------------+
| ANV01 | .5 ton anvil |
| ANV02 | 1 ton anvil |
| ANV03 | 2 ton anvil |
+---------+--------------+
1.15 正则表达式 REGEXP
mysql> select prod_name
-> from products
-> where prod_name REGEXP '.000'
-> order by prod_name;
+--------------+
| prod_name |
+--------------+
| JetPack 1000 |
| JetPack 2000 |
+--------------+
但如果使用like
mysql> select prod_name
-> from products
-> where prod_name like '_000';
Empty set (0.00 sec)
返回的是空,所以like 和 regexp是有区别的,like要求整个列都匹配,而regexp要求部分匹配即可。
注意整个的查询结果是:
JetPack 1000
JetPack 2000
regexp查询:
where prod_name REGEXP '.000'
可以查到结果。
like查询
where prod_name like '.000'
查询不到结果,like要求的是整个行除了前面的.之外都一样。
比如如果查询为:
where prod_name like '_etPack 2000'
是可以查到结果的。
mysql> select prod_name
-> from products
-> where prod_name like '_etPack 1000';
+--------------+
| prod_name |
+--------------+
| JetPack 1000 |
+--------------+
1 row in set (0.00 sec)
1.16 正则表达式 |
mysql> select prod_name
-> from products
-> where prod_name regexp '1000|2000'
-> order by prod_name;
+--------------+
| prod_name |
+--------------+
| JetPack 1000 |
| JetPack 2000 |
+--------------+
| 符号左右不能有空格
1.17 正则表达式 [] 匹配几个字符之一
mysql> select prod_name
-> from products
-> where prod_name regexp '[123] ton'
-> order by prod_name;
+-------------+
| prod_name |
+-------------+
| 1 ton anvil |
| 2 ton anvil |
+-------------+
[123]中满足的都返回
正如所见,[]是另一种形式的OR语句。事实上,正则表达式[123]Ton为[1|2|3]Ton的缩写,也可以使用后者。但是,需要用[]来定义OR语句查找什么。
1.18 [] 匹配范围使用 -
集合可用来定义要匹配的一个或多个字符。例如,下面的集合将匹配数字0到9:
[0123456789]
为简化这种类型的集合,可使用-来定义一个范围。下面的式子功能上等同于上述数字列表:
[0-9]
此外,范围不一定只是数值的,[a-z]匹配任意字母字符。
mysql> select prod_name
-> from products
-> where prod_name REGEXP '[1-5] Ton'
-> order by prod_name;
+--------------+
| prod_name |
+--------------+
| .5 ton anvil |
| 1 ton anvil |
| 2 ton anvil |
+--------------+
1.19 匹配特殊字符 使用转义 \
mysql> select vend_name
-> from vendors
-> where vend_name REGEXP '.'
-> order by vend_name;
+----------------+
| vend_name |
+----------------+
| ACME |
| Anvils R Us |
| Furball Inc. |
| Jet Set |
| Jouets Et Ours |
| LT Supplies |
+----------------+
这并不是期望的输出,.匹配任意字符,因此每个行都被检索出来。
为了匹配特殊字符,必须用\为前导。\-表示查找-,\.表示查找.。
mysql> select vend_name
-> from vendors
-> where vend_name regexp '\.'
-> order by vend_name;
+--------------+
| vend_name |
+--------------+
| Furball Inc. |
+--------------+
存在找出你自己经常使用的数字、所有字母字符或所有数字字母字符等的匹配。为更方便工作,可以使用预定义的字符集,称为字符类。


mysql> select prod_name
-> from products
-> where prod_name REGEXP '\([0-9] sticks?\)'
-> order by prod_name;
+----------------+
| prod_name |
+----------------+
| TNT (1 stick) |
| TNT (5 sticks) |
+----------------+
[0-9]匹配任意数字(这个例子中为1和5),sticks?匹配stick和sticks(s后的?使s可选,因为?匹配它前面的任何字符的0次或1次出现),\)匹配)。没有?,匹配stick和sticks会非常困难。
mysql> select prod_name
-> from products
-> where prod_name REGEXP '[[:digit:]]{4}'
-> order by prod_name;
+--------------+
| prod_name |
+--------------+
| JetPack 1000 |
| JetPack 2000 |
+--------------+
[[:digit:]]{4}要求是数字,且出现了4次。
1.20 定位符

mysql> select prod_name
-> from products
-> where prod_name regexp '^[0-9\.]'
-> order by prod_name;
+--------------+
| prod_name |
+--------------+
| .5 ton anvil |
| 1 ton anvil |
| 2 ton anvil |
+--------------+
匹配串的开始。因此,[0-9\.]只在.或任意数字为串中第一个字符时才匹配它们。
是数字或者是 .
1.21 计算字段
存储在数据库表中的数据一般不是应用程序所需要的格式。下面举几个例子。
- 如果想在一个字段中既显示公司名,又显示公司的地址,但这两个信息一般包含在不同的表列中。
- 城市、州和邮政编码存储在不同的列中(应该这样),但邮件标签打印程序却需要把它们作为一个恰当格式的字段检索出来。
- 列数据是大小写混合的,但报表程序需要把所有数据按大写表示出来。
- 物品订单表存储物品的价格和数量,但不需要存储每个物品的总价格(用价格乘以数量即可)。为打印发票,需要物品的总价格。
- 需要根据表数据进行总数、平均数计算或其他计算。
在上述每个例子中,存储在表中的数据都不是应用程序所需要的。我们需要直接从数据库中检索出转换、计算或格式化过的数据;而不是检索出数据,然后再在客户机应用程序或报告程序中重新格式化。
这就是计算字段发挥作用的所在了。与前面各章介绍过的列不同,计算字段并不实际存在于数据库表中。计算字段是运行时在SELECT语句内创建的。
1.22 使用Concat 拼接串
mysql> select Concat(vend_name, '(',vend_country,')')
-> from vendors
-> order by vend_name;
+-----------------------------------------+
| Concat(vend_name, '(',vend_country,')') |
+-----------------------------------------+
| ACME(USA) |
| Anvils R Us(USA) |
| Furball Inc.(USA) |
| Jet Set(England) |
| Jouets Et Ours(France) |
| LT Supplies(USA) |
+-----------------------------------------+
1.23 使用函数


1.24 使用RTrim 函数去掉空格
+------------------------------------------------------+
| Concat(RTrim(vend_name),'(',RTrim(vend_country),')') |
+------------------------------------------------------+
| ACME(USA) |
| Anvils R Us(USA) |
| Furball Inc.(USA) |
| Jet Set(England) |
| Jouets Et Ours(France) |
| LT Supplies(USA) |
+------------------------------------------------------+
RTrim()函数去掉值右边的所有空格。通过使用RTrim(),各个列都进行了整理。
1.25 使用别名 AS
mysql> select concat(Rtrim(vend_name),'(',Rtrim(vend_country),')') as vend_title
-> from vendors
-> order by vend_name;
+------------------------+
| vend_title |
+------------------------+
| ACME(USA) |
| Anvils R Us(USA) |
| Furball Inc.(USA) |
| Jet Set(England) |
| Jouets Et Ours(France) |
| LT Supplies(USA) |
+------------------------+
1.26 执行计算
检索信息如下,计算quantity * iten_price
mysql> select prod_id, quantity, item_price
-> from orderitems
-> where order_num = 20005;
+---------+----------+------------+
| prod_id | quantity | item_price |
+---------+----------+------------+
| ANV01 | 10 | 5.99 |
| ANV02 | 3 | 9.99 |
| TNT2 | 5 | 10.00 |
| FB | 1 | 10.00 |
+---------+----------+------------+
执行计算,然后使用别名
mysql> select prod_id,quantity,item_price, quantity*item_price as expandede_price
-> from orderitems
-> where order_num=20005;
+---------+----------+------------+-----------------+
| prod_id | quantity | item_price | expandede_price |
+---------+----------+------------+-----------------+
| ANV01 | 10 | 5.99 | 59.90 |
| ANV02 | 3 | 9.99 | 29.97 |
| TNT2 | 5 | 10.00 | 50.00 |
| FB | 1 | 10.00 | 10.00 |
+---------+----------+------------+-----------------+
1.27 使用大写转换函数 Upper
mysql> select vend_name, Upper(vend_name) as vend_name_upcase
-> from vendors
-> order by vend_name;
+----------------+------------------+
| vend_name | vend_name_upcase |
+----------------+------------------+
| ACME | ACME |
| Anvils R Us | ANVILS R US |
| Furball Inc. | FURBALL INC. |
| Jet Set | JET SET |
| Jouets Et Ours | JOUETS ET OURS |
| LT Supplies | LT SUPPLIES |
+----------------+------------------+
1.28 使用发音类似soundex函数
返回所有发音类似查询的行
加入有如下的查询,但是数据在存储的时候名字存错了,存的是Y.Lee。
mysql> select cust_name, cust_contact
-> from customers
-> where cust_contact = 'Y.Lie';
Empty set (0.00 sec)
这时候可以使用soundex函数查询发音类似的。
注意函数调用的方式
mysql> select cust_name, cust_contact
-> from customers
-> where Soundex(cust_contact) = Soundex('Y.Lie');
+-------------+--------------+
| cust_name | cust_contact |
+-------------+--------------+
| Coyote Inc. | Y Lee |
+-------------+--------------+
1 row in set (0.00 sec)
1.29 日期和时间处理函数
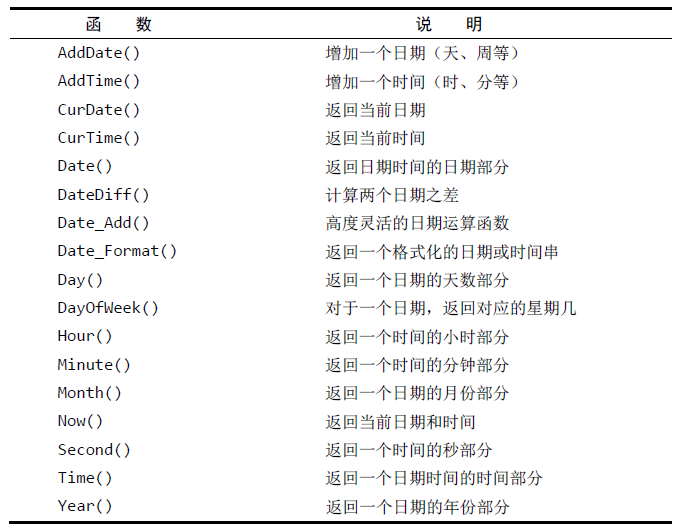
首先需要注意的是MySQL使用的日期格式。无论你什么时候指定一个日期,不管是插入或更新表值还是用WHERE子句进行过滤,日期必须为格式yyyy-mm-dd。因此,2005年9月1日,给出为2005-09-01。虽然其他的日期格式可能也行,但这是首选的日期格式,因为它排除了多义性(如,04/05/06是2006年5月4日或2006年4月5日或2004年5月6日或……)。
比如要检索日期为2005-09-01,如下:
mysql> select cust_id, order_num
-> from orders
-> where order_date = '2005-09-01';
+---------+-----------+
| cust_id | order_num |
+---------+-----------+
| 10001 | 20005 |
+---------+-----------+
1 row in set (0.00 sec)
但如果日期存储的时候不光存日期还有时间等信息。则检索失败。
可以调用Date函数,返回日期为给定的行。
mysql> select cust_id,order_num
-> from orders
-> where Date(order_date) between '2005-09-01' and '2005-09-30';
+---------+-----------+
| cust_id | order_num |
+---------+-----------+
| 10001 | 20005 |
| 10003 | 20006 |
| 10004 | 20007 |
+---------+-----------+
3 rows in set (0.00 sec)
或者
直接指定年份和月份
mysql> select cust_id, order_num
-> from orders
-> where Year(order_date) = 2005 and Month(order_date) = 9;
+---------+-----------+
| cust_id | order_num |
+---------+-----------+
| 10001 | 20005 |
| 10003 | 20006 |
| 10004 | 20007 |
+---------+-----------+
1.30 数值处理函数
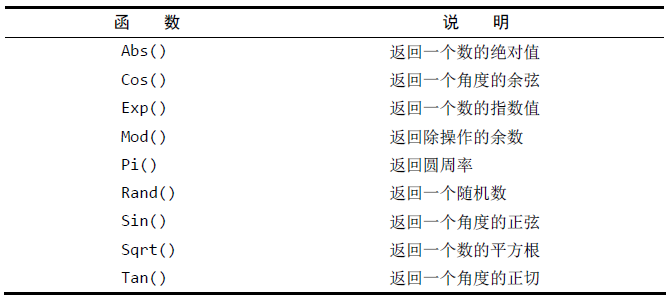
1.31 聚集函数
我们经常需要汇总数据而不用把它们实际检索出来,为此MySQL提供了专门的函数。使用这些函数,MySQL查询可用于检索数据,以便分析和报表生成。这种类型的检索例子有以下几种。


1.31.1 AVG函数
mysql> select AVG(prod_price) as avg_price
-> from products;
+-----------+
| avg_price |
+-----------+
| 16.133571 |
+-----------+
AVG()也可以用来确定特定列或行的平均值。下面的例子返回特定供应商所提供产品的平均价格:
mysql> select AVG(prod_price) as avg_price
-> from products
-> where vend_id = 1003;
+-----------+
| avg_price |
+-----------+
| 13.212857 |
+-----------+
1 row in set (0.00 sec)
1.31.2 COUNT函数
返回行的数目
- 使用COUNT(*)对表中行的数目进行计数,不管表列中包含的是空值(NULL)还是非空值。
- 使用COUNT(column)对特定列中具有值的行进行计数,忽略NULL值。
mysql> select count(*) as num_cust
-> from customers;
+----------+
| num_cust |
+----------+
| 5 |
+----------+
1 row in set (0.00 sec)
指定值后忽略空行
mysql> select count(cust_email) as num_cust
-> from customers;
+----------+
| num_cust |
+----------+
| 3 |
+----------+
1.31.3 MAX函数
MAX()返回指定列中的最大值。MAX()要求指定列名,如下所示:
mysql> select MAX(prod_price) as max_price
-> from products;
+-----------+
| max_price |
+-----------+
| 55.00 |
+-----------+
1 row in set (0.00 sec)
1.31.4 MIN函数
MIN()的功能正好与MAX()功能相反,它返回指定列的最小值。与MAX()一样,MIN()要求指定列名,如下所示:
mysql> select MIN(prod_price) as min_price
-> from products;
+-----------+
| min_price |
+-----------+
| 2.50 |
+-----------+
1 row in set (0.00 sec)
1.31.5 SUM函数
下面举一个例子,orderitems表包含订单中实际的物品,每个物品有相应的数量(quantity)。可如下检索所订购物品的总数(所有quantity值之和):
mysql> select SUM(quantity) as items_ordered
-> from orderitems
-> where order_num = 20005;
+---------------+
| items_ordered |
+---------------+
| 19 |
+---------------+
1 row in set (0.00 sec)
对计算的结果求和。
mysql> select SUM(item_price*quantity) as total_price
-> from orderitems
-> where order_num = 20005;
+-------------+
| total_price |
+-------------+
| 149.87 |
+-------------+
1 row in set (0.00 sec)
1.32 聚集不同值 DISTINCT
mysql> select AVG(DISTINCT prod_price) as avg_price
-> from products
-> where vend_id = 1003;
+-----------+
| avg_price |
+-----------+
| 15.998000 |
+-----------+
组合聚集函数
mysql> select count(*) as num_item,
-> MIN(prod_price) as price_min,
-> MAX(prod_price) as price_max,
-> AVG(prod_price) as price_avg
-> from products;
+----------+-----------+-----------+-----------+
| num_item | price_min | price_max | price_avg |
+----------+-----------+-----------+-----------+
| 14 | 2.50 | 55.00 | 16.133571 |
+----------+-----------+-----------+-----------+
1 row in set (0.00 sec)
1.33 数据分组 group by
group by 指示Mysql按照指定的规则分组。
mysql> select vend_id,count(*) as num_prods
-> from products
-> group by vend_id;
+---------+-----------+
| vend_id | num_prods |
+---------+-----------+
| 1001 | 3 |
| 1002 | 2 |
| 1003 | 7 |
| 1005 | 2 |
+---------+-----------+
4 rows in set (0.00 sec)
上面的SELECT语句指定了两个列,vend_id包含产品供应商的ID,num_prods为计算字段(用COUNT(*)函数建立)。GROUP BY子句指示MySQL按vend_id排序并分组数据。这导致对每个vend_id而不是整个表计算num_prods一次。从输出中可以看到,供应商1001有3个产品,供应商1002有2个产品,供应商1003有7个产品,而供应商1005有2个产品。
在具体使用GROUP BY子句前,需要知道一些重要的规定。
- group by 子句可以包含任意数组的列。这使得能对分组进行嵌套,为数据分组提供更细致的控制。
- 如果在group by子句中嵌套了分组,数据将在最后规定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算。
- group bu 子句中列出的每个列都必须是检索列或有效的表达式。如果在select中使用表达式,则必须在group by子句中指定相同的表达式。不能使用别名。
- 除聚集计算语句外,selec语句中的每个列都必须在group by子句中给出。
- 如果分组列中具有NULL值,则NULL将作为一个分组返回,如果列中有多行NULL值,他们将分为一组。
- group bu 子句必须出现在where子句之后,order by子句之前。
1.34 使用Having 过滤分组
Having与Where不同,Where过滤的是行,没有分组的概念。
如果不过滤分组得到如下。
mysql> select cust_id, count(*) as orders
-> from orders
-> group by cust_id;
+---------+--------+
| cust_id | orders |
+---------+--------+
| 10001 | 2 |
| 10003 | 1 |
| 10004 | 1 |
| 10005 | 1 |
+---------+--------+
4 rows in set (0.00 sec)
使用Having过滤分组得到如下:
mysql> select cust_id, count() as orders
-> from orders
-> group by cust_id
-> having count() >= 2;
+---------+--------+
| cust_id | orders |
+---------+--------+
| 10001 | 2 |
+---------+--------+
1 row in set (0.00 sec)
那么,有没有在一条语句中同时使用WHERE和HAVING子句的需要呢?事实上,确实有。假如想进一步过滤上面的语句,使它返回过去12个月内具有两个以上订单的顾客。为达到这一点,可增加一条WHERE子句,过滤出过去12个月内下过的订单。然后再增加HAVING子句过滤出具有两个以上订单的分组。
mysql> select vend_id, count() as num_prods
-> from products
-> where prod_price >= 10
-> group by vend_id
-> Having count() >= 2;
+---------+-----------+
| vend_id | num_prods |
+---------+-----------+
| 1003 | 4 |
| 1005 | 2 |
+---------+-----------+
2 rows in set (0.00 sec)
概念篇
1. 什么是Mysql
数据的所有存储检索、管理和处理实际上是由数据库软件——DBMS(数据库管理系统)完成的。MySQL是一种DBMS,即它是一种数据库软件。

2. BTree和B+Tree详解
3. B+每个结点的大小为多少?
一般一个结点设置为一个页的大小(一般16K),可以充分利用磁盘预读原理,不浪费。
4. 聚集索引与辅助索引
聚集索引与辅助索引不同之处就是每个叶子结点存放的是否是一整行的信息。
聚集索引的叶子节点包含完整的行数据,而非聚集索引的叶子节点存储的是每行数据的辅助索引键 + 该行数据对应的聚集索引键(主键值)。
聚集索引:
InnoDB存储引擎表是索引组织表结构,即表中数据都是按照主键顺序进行存放的。而聚集索引就是按照每张表的主键构造一棵B+树,同时叶子结点中存放的即为表中一行一行的数据,所以聚集索引的叶子结点也被称为数据结点。
辅助索引:
其和聚集索引的最大区别在于辅助索引叶子结点并不包含行记录的全部数据。
当通过辅助索引来寻找数据时,InNoDB存储引擎会先遍历辅助索引并通过叶子结点获得某个辅助索引键对应的聚集索引建,然后再通过聚集索引来找到一个完整的行记录。
5. 回表
回表就是先进行辅助索引,然后在得到的表中再进行聚集索引。
6. ACID
7. InNoDB如何解决幻读
8. redo log,undo log,bin log
9. 什么是当前读和快照读
- 当前读:
像select lock int share mode(共享锁),select for updata;updata,insert,delete(排它锁)这些操作都是一种当前读,为什么叫当前读?就是它读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。 - 快照度:
像不加锁的select操作都是快照读,即不加锁的非阻塞读;快照读的前提是隔离级别不是串行级别,串行级别下的快照读会退化成当前读;之所以出现快照读的情况,是基于提高并发控制性能的考虑,快照读的实现是基于多版本并发控制,即MVCC,可以认为MVCC是行锁的一个变种,但它在很多情况下,避免了加锁操作,降低了开销;既然是基于多版本,即快照读可能读到的并不一定是数据的最新版本,而有可能是之前的历史版本。
10. MVCC学习
数据库并发场景有三种,分别为:
- 读-读:不存在任何问题,也不需要并发控制
- 读-写:有线程安全问题,可能会造成事务隔离性问题,可能遇到脏读,幻读,不可重复读
- 写-写:有线程安全问题,可能会存在更新丢失问题,比如第一类更新丢失,第二类更新丢失
备注:
- 第1类丢失更新:事务A撤销时,把已经提交的事务B的更新数据覆盖了;
- 第2类丢失更新:事务A覆盖事务B已经提交的数据,造成事务B所做的操作丢失

-f81b26a023b244368f8b4b40ee96bf47.JPG)
评论区